




The US Army War College Tested Four AI Systems on Its Capstone Exam. They All Passed.


“Can AI Pass the US Army War College?” by Kevin Boyce, John Nagl, and Kristan Wheaton at US Army War College Parameters (April 2026).
This latest US Army War College report finds that all four commercial AI systems they tested in early 2026 passed the rigorous USAWC oral comprehensive examination. The authors designed “MilBench,” a domain-specific benchmark that applied the War College’s standard capstone assessment to ChatGPT, Gemini, Claude, and Grok in conversational mode.
Three faculty panels administered the examination, scoring Claude at a mean GPA of 3.98 (A) and placing ChatGPT, Grok, and Gemini in a statistically indistinguishable B+ cluster. The multi-turn dialogue format exposed performance patterns, including brevity, sycophancy under pressure, and degradation over time, that static benchmarks fail to surface. The authors argue that the results shown below challenge the Department of War’s evaluation of commercial AI for strategic applications and call for domain-specific, dialogue-based assessment standards.
MilBench pilot results, February through March 2026
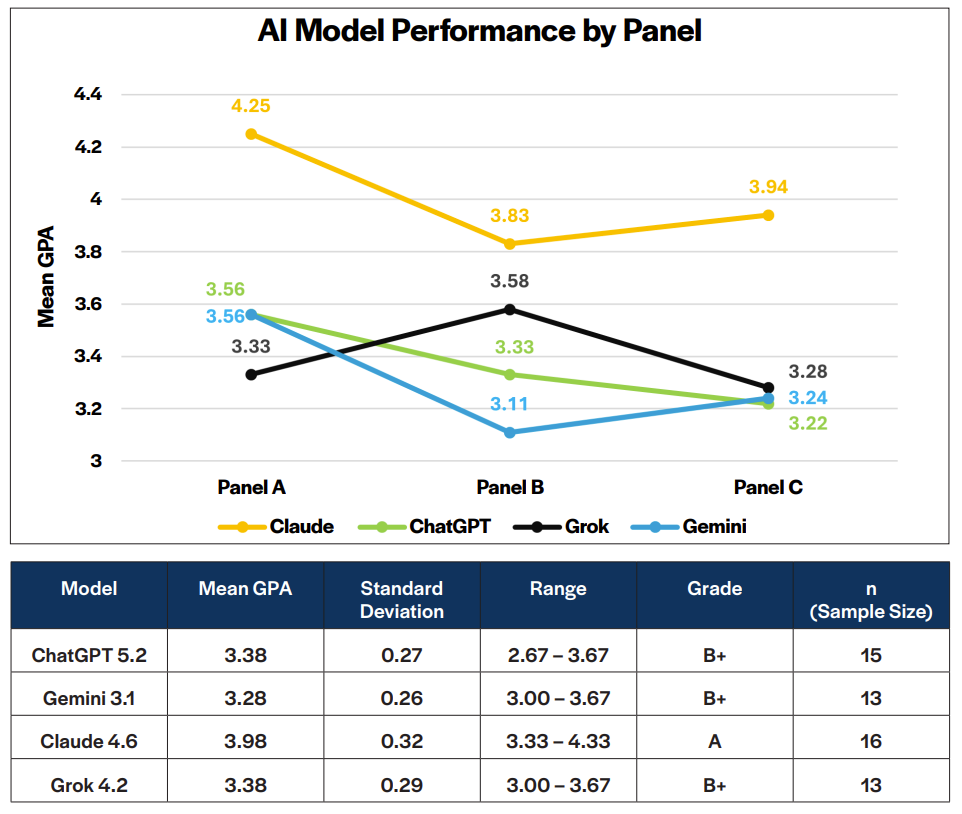
The article concludes that PME institutions must reorient their curricula to cultivate wisdom and judgment, since AI now commands strategic frameworks sufficient to pass the War College capstone. Yet the authors are clear-eyed about what passing reveals: “MilBench observed similar limitations—yielding under pressure, sycophantic responses, degradation, and sensitivity to geopolitics,” and these “constraints reveal how these systems are not ready to be employed in roles where leaders depend on them for high-stakes scenarios.”
The path forward runs through the student, not around them: “students who engage with AI will be better positioned to identify what it does not know and challenge its assumptions,” and “this turns the students into the teachers who ask the right questions of a system that always has an answer but not always the right one.”
Future leaders must possess the judgment to know which questions matter, the wisdom to act when no answers are certain, and the accountability that follows from both.
The authors ground that imperative in a clean distinction, writing that “AI may assist with staff work, data, and analytical processes through the science of control, but it cannot assume the ‘intuition, experience, judgment, morale, and the ability to inspire human beings’ that constitute the art of command and leadership.”
What MilBench establishes, then, is a floor, not a ceiling: “intelligence—command over strategic frameworks, doctrinal vocabulary, and historical precedent—is what MilBench demonstrates commercial AI now possesses,” while “wisdom, understood as the capacity to weigh incommensurable values under uncertainty and to exercise judgment rooted in experience that no training dataset replicates, remains the domain where senior staff college education should concentrate its ambitions.”
“AI-Enabled Wargaming at the U.S. Army Command and General Staff College” (SWJ, January 2026) reaches a parallel conclusion through wargaming experimentation at CGSC, finding that AI-enabled participants identified substantially more risks and branches during exercises while still requiring human oversight to prevent hallucinations and planning errors. Ultimately, while both articles find that AI can enhance the analytical throughput of staff officers, it still cannot replace the human presence, command, and judgment that PME exists to develop.