Science Fiction vs. Science Funding: Comparing What We Imagine to What We Invent
Peter David
Science Fiction is primarily created and consumed for entertainment. Recently, however, it has had an “off label use” as a form of crowdsourcing to generate predictions about the evolution of technology and society. Older science fiction stories described aspects of an imagined future that were eventually borne-out. For example, communication satellites were proposed in 1945 by science fiction author Arthur C. Clarke, 19 years before the first communication satellite was launched.[i] Newer works contain thought-provoking ideas that seem to have the potential to one-day be realized.
Reading individual stories to find creative predictions of plausible future scenarios is one way to take advantage of science fiction as a forward-looking form of crowdsourcing. Another method is to analyze large collections of science fiction stories in bulk to identify trends and patterns that emerge when the work of many authors is considered. The TRADOC Mad Scientist Initiative[ii] recently held a science fiction short story contest soliciting stories about warfare in the years 2030 to 2050. The Mad Scientist personnel judged each story and selected a winner and runners-up that contained creative and compelling visions of how warfare may evolve in the coming decades. This article describes the results of a statistical analysis of the entire corpus of stories to identify common themes that emerge when all stories are considered together.
Our goal is to compare the ideas about future warfare imagined by science fiction authors with the goals of DoD research agencies (Figure 1). Areas where science fiction and science funding overlap may indicate where science fiction authors anticipate technology that is actively being developed. Areas where the two bodies of ideas differ can tell us what we might be surprised about if we relied exclusively on science fiction to anticipate the future, and what forward-looking ideas may be overlooked by the DoD research community.
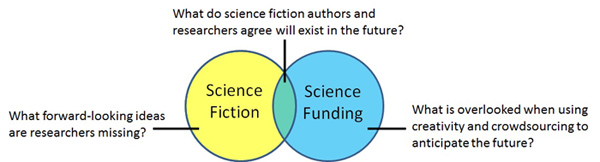
Figure 1 – The goal of this analysis is to understand how the future-looking ideas evoked by science fiction stories about warfare in the coming decades matches the goals of the DoD research agencies that are preparing for the future battlefield.
Data
The science fiction corpus consisted of 104 short stories, selected for relevance from 156 stories submitted to the contest. There were several rules and restrictions that governed story submissions:
- Authors must be at least 18 years old
- Stories have a 5,000-word limit
- Stories must not have been previously published
- The story must respond to the writing prompt: Warfare in 2030-2050
The research solicitation corpus was taken from the historical Small Business Innovative Research (SBIR) solicitations available on the DoD SBIR web site.[iii] The SBIR program provides research and development funding to small businesses. The DoD’s SBIR program issues quarterly solicitations for 6.1 (Basic Research), 6.2 (Applied Research), and 6.3 (Advanced Technology Development) research. Over 25,000 solicitations have been issued since the program began in 1983,[iv] with most of these solicitations resulting in funded research projects. Since 2000, the DoD SBIR program has provided between $460M and $2.3B of funding annually.[v] The SBIR solicitations call for research in a diverse set of fields – virtually every research area relevant to the military is represented in the SBIR portfolio.
The two corpora used are summarized in Table 1.
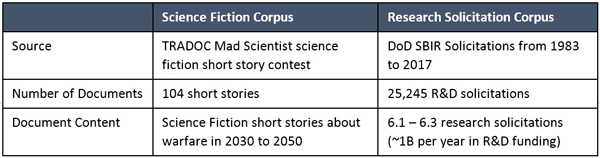
Table 1 - Comparison of the two data sets used in this analysis
Data Modeling
With over 25,000 documents in the research solicitation corpus, it is impractical to read and hand-code each story and research topic.[vi] What is needed is a method of automatically modeling the content of a large collection of unstructured text so that the topics discussed can be characterized and so that there is a principled, quantitative way of comparing the content of two sets of text data. The analysis discussed here used a Statistical Topic Modeling (STM) algorithm[vii] to discover the topics of discussion in the data and to infer the degree to which each document is “about” each topic. The inputs and outputs of the STM algorithm are illustrated in Figure 2.

Figure 2 – The inputs (unstructured text documents) and outputs (topics and a topic/document mapping) of a Statistical Topic Modeling (STM) algorithm.
A STM algorithm takes as input, a collection of unstructured text documents (left side of Figure 2). Using statistics based on word counts and co-occurrence, it produces a set of topics and table defining the degree to which each document is “about” a topic. (right side of Figure 2). A topic can be thought of as a group of words that tend to co-occur throughout the corpus. Topics are actually probability distributions over all the words in the corpus vocabulary – we take advantage of this detail in our analysis below. Topics are typically visualized as a weighted group of words sorted in descending order of importance for the topic. In the example of Figure 2, the topic “turbine, engine, combusting, power, … indicates discussion of turbines, and the topic “efficiency, advanced, power, weight, …” indicates discussion of system performance. Each document is modeled as a mixture of topics. For example, based on the pie chart for the first document in Figure 2, we can say that it primarily discusses turbines but has some discussion of system performance.
Figure 2 illustrates the idea of a document/topic model with three topics.
We created two topic models: one for the science fiction corpus and one for the research solicitation corpus. Independent, per-corpus models avoid the problem where discussion in the larger, 25,254-document research solicitation corpus overwhelms the discussion in the 104-document science fiction corpus. Each topic model was created with 100 topics[viii] to capture the broad scope of the discussion in each data set.
Results
Selected topics from each model are shown in Table 2 and Table 3. Each row contains the highest-weighted words in the topic. The background color of each cell is coded, like a heat map, to visually indicate the relative weight of the word within the topic.
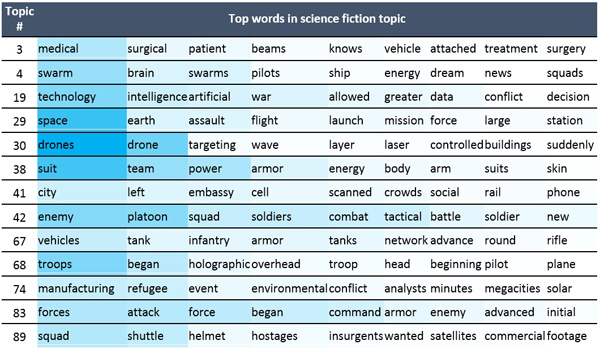
Table 2 – Some of the 100 topics built from the science fiction corpus
The science fiction topics in Table 2 show a blend of narrative elements and technological themes. Some topics, such as #3 (medical, surgical, patient, …) and #19 (technology, intelligence, artificial, …) are the signatures of stories that contain discussion of advanced medical or AI technologies. Other topics, such as #83 (forces, attack, force) and #42 (enemy, platoon, squad) are related to narrative elements of stories’ setting and plot.
In contrast, the research solicitation topics in Table 3 show a focus exclusively on technology areas. For example, topics such as #21 (infrared, detector, …) and #24 (composite, materials, …) suggest discussion of research into infrared imaging and advanced materials.
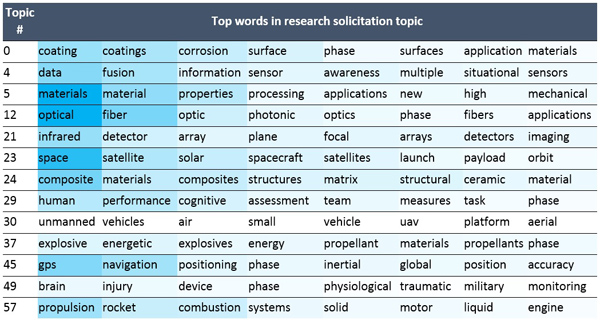
Table 3 – Some of the 100 topics build from the research solicitation corpus
Common Themes in Science Fiction and Science Funding
Even in these small samples of topics, we can identify overlaps in the types of technologies discussed. For example, science fiction topic #30 (drone, drones, targeting) and research solicitation topic #30 (unmanned, vehicles, air) both appear to represent discussion of remotely piloted aircraft. The fact that both happen to be topic #30 in their respective models is coincidence. The topic numbers assigned by the STM algorithm are arbitrary.
Because topic models are quantitative models of corpus content, it is possible to define measures of topic similarity and computationally find areas of overlap and disjunction between the science fiction stories and the research solicitations. In this analysis, we use cosine similarity as the measure of similarity between two topics. The formula for cosine similarity is:
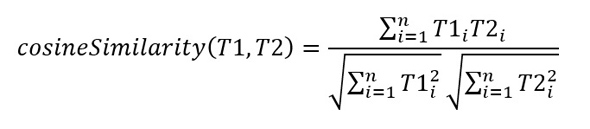
Where T1 is a topic from the science fiction topic model, T2 is a topic from the research solicitation topic model, n is the number of words in the combined vocabulary of the two corpora, and T1i and T2i are the weights of the word i in each topic. The cosineSimilarity function returns a value between 0 and 1[ix]. A value of 1 means that the topics are identical – each word in the vocabulary has the same weight in both topics. A value of 0 means that the topics are completely dissimilar, with no non-zero-weighted words in common.
Using this measure of similarity, we ranked each of the 10,000 pairs of topics across corpora. The top 5 most similar topics between the science fiction stories and research solicitations are shown in Table 4.

Table 4 – Top 5 best matches between the science fiction topics and the research solicitation topics
Using the STM algorithm’s mapping between topics and documents that are “about” each topic, we can find examples of stories and research solicitations linked to the overlap topics in Table 4. Below, text samples from a science fiction story and a research solicitation from a high-overlap topic are shown to give a sense for the way ideas represented by an overlap topic are discussed in each corpus.
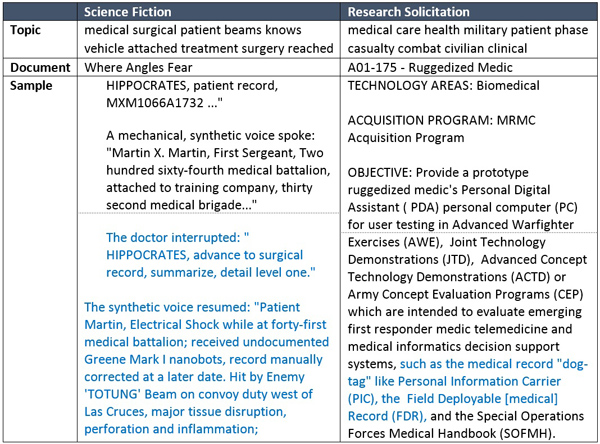
Table 5 – Example of a science fiction story and a research solicitation that are “about” one of the high-overlap topics.
Themes Unique to Science Fiction or Science Funding
Using the same cosineSimilarity measure used to identify topics in common between the science fiction and research solicitation corpora, we can identify topics from one corpus that are most unlike any topics in the other corpus. Table 6 shows the science fiction topics that were least like any topic in the research solicitation data set. These topics largely reflect narrative language (didn’t, wasn’t, started, got, …) or plot elements (world, war, …).
One interesting finding in Table 6 is the topic troops, began, holographic, overhead, … The Mad Scientist initiative’s analysis of the science fiction corpus[x] found that heads-up displays, virtual reality, and augmented reality were frequent technology themes in the story collection. Yet, this analysis shows that the term holographic was in a fiction-only topic. Further investigation of the complete set of 100 research solicitation topics found that the terms virtual and reality only appeared rarely in the topic model, and in contexts related to training simulations. The term augmented was not present in highest-weighted 50 words of any research topic. The idea of using these technologies in an operational setting is not well-represented in the research solicitations.
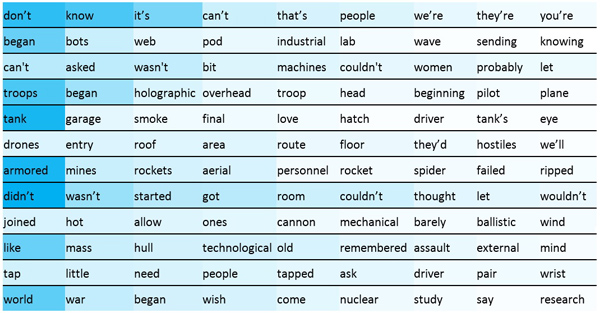
Table 6 – Science fiction topics least like any research solicitation topic
Table 7 shows the research solicitation topics that were least like any topic in the science fiction corpus. The research-only topics represent detailed technical aspects of specific technologies or applications that were not present in the science fiction stories.
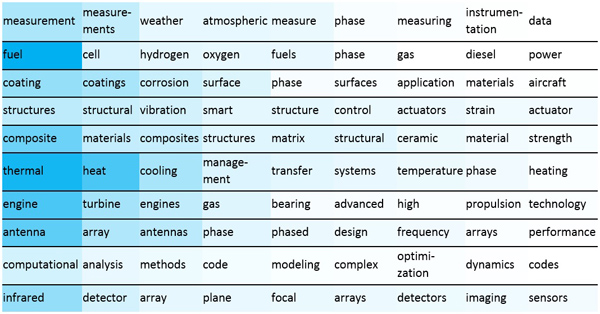
Table 7 – Research solicitation topics least like any science fiction topic
Conclusions
We used a quantitative method of summarizing unstructured text to build topical models of the content of a collection of warfare-focused science fiction stories and a collection of DoD research solicitations. Using a simple similarity measure, we automatically compared the two sets of documents to find themes that were present in both sets of data, and ideas that were expressed in one set of documents only.
Figure 3 is a qualitative interpretation of the quantitative comparison of the two corpora. Themes present in both science fiction and research solicitations are drawn from the more glamorous or ambitious elements of funded research. The science fiction stories analyzed tended towards depiction of these “big picture” types of technologic advances. Topics representing the “grunt work” of research – materials research, vibration and heat management, etc. – were not highlighted in the works of fiction. Science fiction, on the other hand, devoted substantial content to discussion of how multiple technologies might interact, and the effects of multiple advanced technologies on individuals and society.
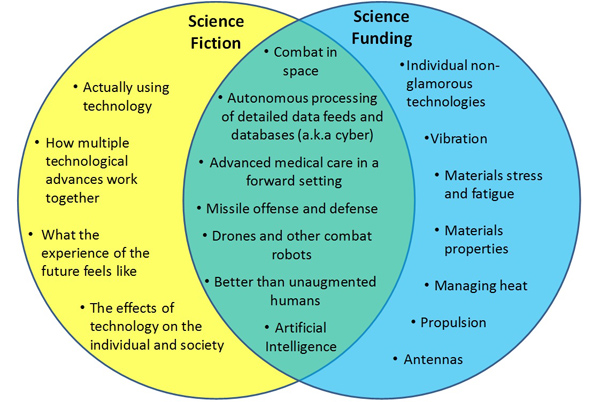
Figure 3 – Qualitative interpretation of the quantitative comparison of science fiction stories and research solicitations.
Acknowledgements
The author thanks the TRADOC Mad Scientist initiative for holding the 2017 science fiction writing contest and for making the set of collected stories available for this analysis. The author is grateful to Decisive Analytics Corporation for access to the analytics software and computing hardware used to perform this work. Finally, we want to thank the Army Research Laboratory’s Computer and Information Sciences Division for their support of this work.
Research was sponsored by the Army Research Laboratory and was accomplished under Agreement Number W911QX-15-C-0031 (TPOC Dr. Timothy Hanratty). The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the Army Research Laboratory or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation herein.
End Notes
[i] P. F. Hamilton, “Can science fiction writers predict trends in technology’s future?,” New Statesman, 13-Oct-2014.
[ii] https://community.apan.org/wg/tradoc-g2/mad-scientist/
[iii] 708 documents available at http://www.acq.osd.mil/osbp/sbir/solicitations/archives.shtml as of the 2017.2/2017.B round of solicitations.
[iv] Each of the documents contains multiple research topics. Automated topic extraction occasionally failed due to the wide variety of formatting conventions used across the corpus. Most topics were extracted, producing 25,245 topic-documents for analysis.
[v] https://www.sbir.gov/awards/annual-reports
[vi] Although, the Mad Scientist group did manually evaluate the science fiction corpus: L. Shabro and A. Winer, “U.S. Army TRADOC Mad Scientist Sci-Fi Stories,” Small Wars Journal, Aug. 2017.
[vii] D. M. Blei, A. Y. Ng, and M. I. Jordan, “Latent dirichlet allocation,” the Journal of machine Learning research, vol. 3, pp. 993–1022, 2003.
[viii] We supplied the Latent Dirichlet Allocation algorithm with these parameters: 100 topics, 1000 iterations of sampling, alpha = 0.1, beta = 0.01.
[ix] Our STM implementation does not assign negative weights to words, so cosineSimilarity will never return a negative value.
[x] Shabro and Winer, 2017